
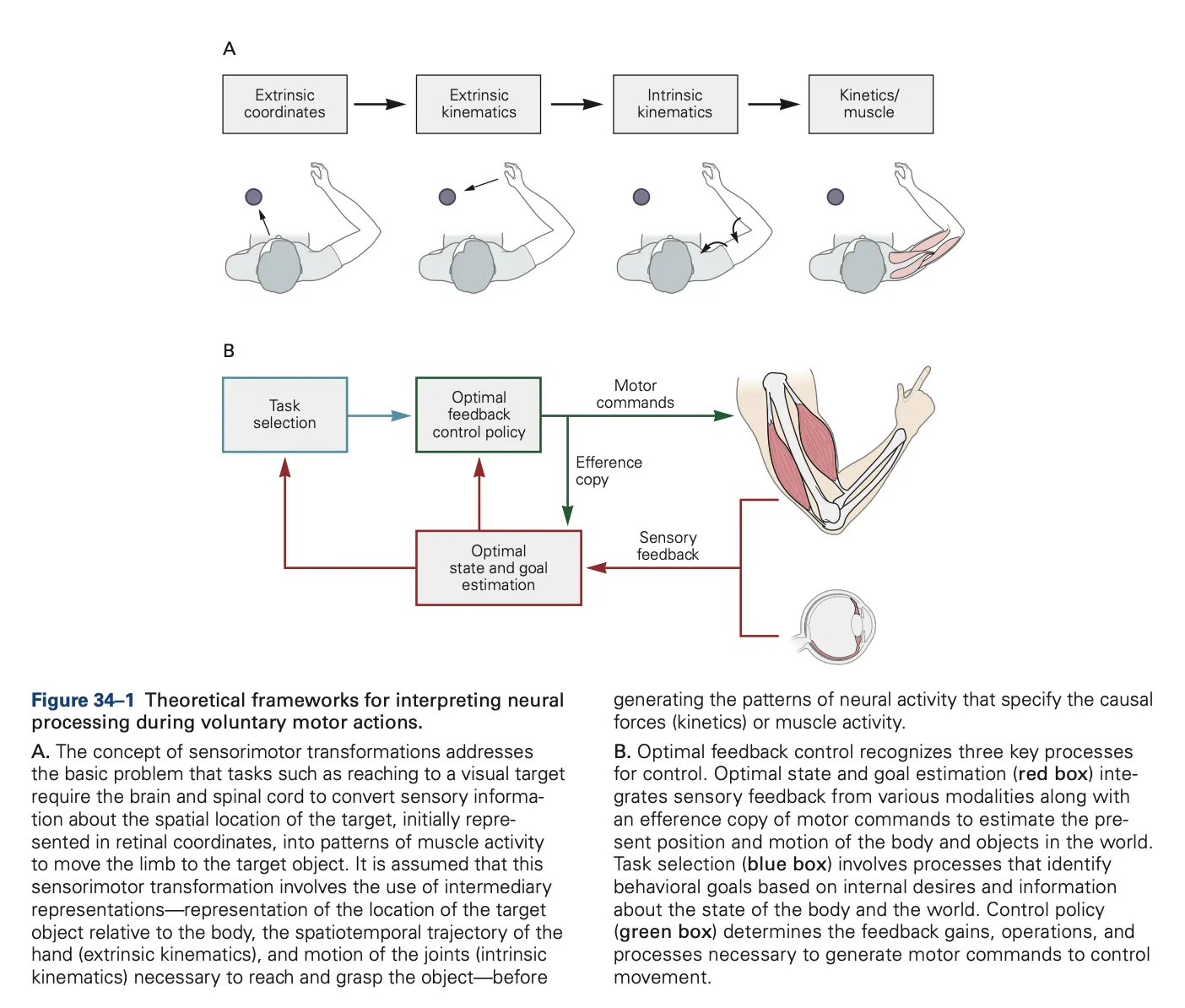
6.4 Predictoin errors drive adaptation of internal models
모델링 기초
Mazzoni et al.(2006)의 연구
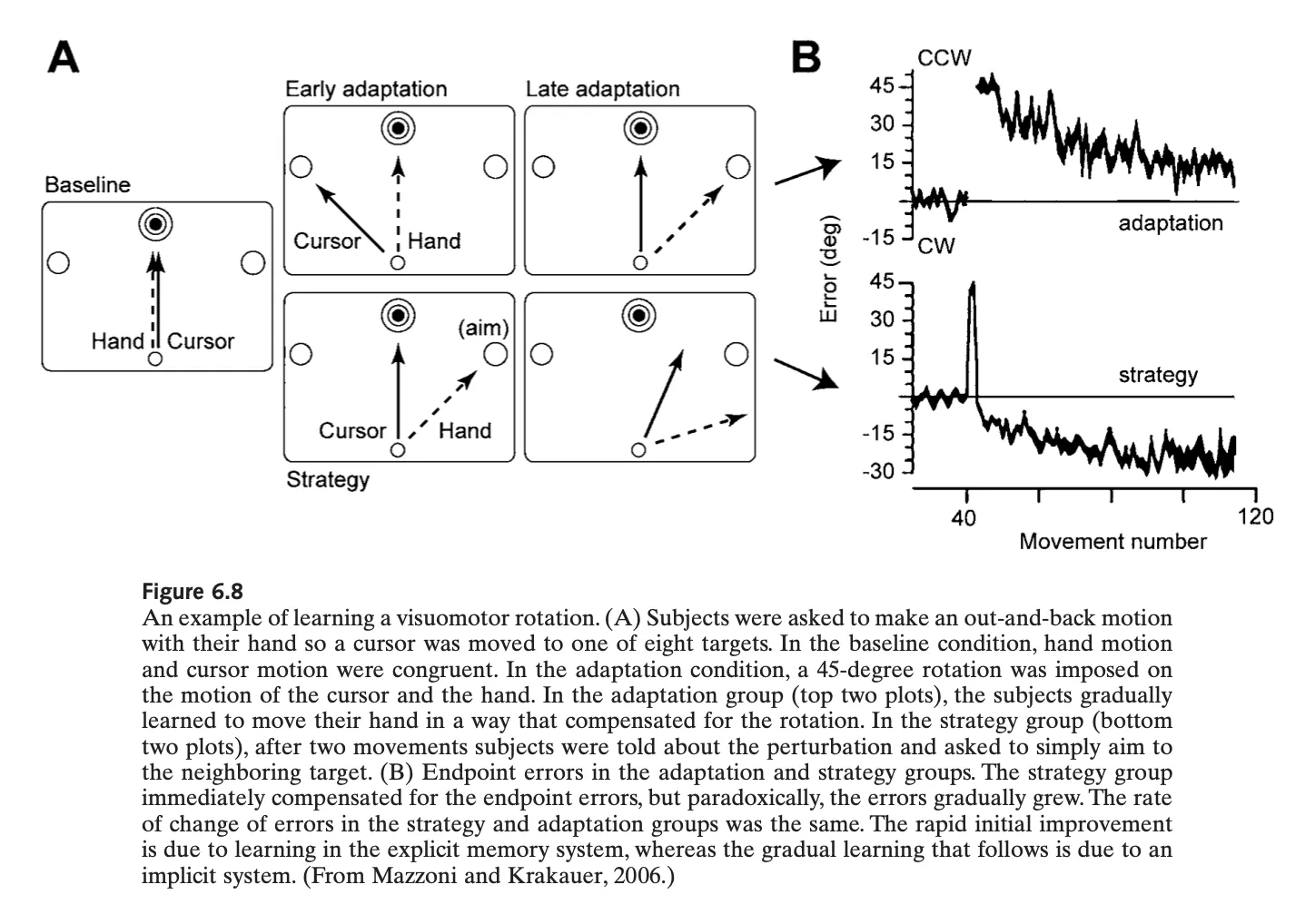
45도 perdurbation - visually → hidden state
는 타겟의 방향
motor command - move the hand in direction
운동명령 u를 실행하면, 손은 를 향해 움직임.
그 결과 시각 피드백 = 로 주어지게 됨. 손의 움직임에 대한 시각적 관찰.
나는 를 향했지만, 시각피드백은 손의 움직임 + 만큼의 왜곡이 더해진 형태로 나타나게 됨.
한편, 운동시스템은 인터널모델을 활용하여 운동명령 에 따라 일어난 움직임의 감각 귀결에 대한 예측
(이어야 함, 시뮬레이션 결과)을 생성함. 내가 를 향한 운동명령 를 실행했으니, 나의 눈에는 저러저러한 모습이 보이게 될 것이다. 이러이러하면 저러저러하다.{후썰}
그런데, 관찰된 감각 귀결은
임.
예측된 감각귀결과 관찰된 감각귀결 사이의 차이를 sensory prediction error라고 부름. SPE
에서 을 뺀 값을 오차의 크기로 정의함. 실제 관측이 기준이고, 그 관측과 예측 사이의 차이를 계산(예측을 업데이트하기 위해)
이 SPE를 이용하여, 을 업데이트한다. 를 알 수 있다면, 을 더 정확하게 구할 수 있으므로. SPE가 0이 될 때까지 반복되어야 함.
→ [u를 실행했다면 내 손이 어디를 향할지에 대한추정]
이때, , , 변경된 운동명령이 필요함.
의 방향에 위치한 타겟에 대해, 운동명령 을 생성한다. 이 운동명령은 커서를 타겟으로 향하도록 함. 가려고 하는 방향에 더해진 perturbation r 만큼 반대로 향하는 것을 의미.
주어진 방해 r을 추정하고, 그 크기를 보상할 수 있는 움직임을 형성한다는 것을 뜻함.
80 시행정도를 반복하면, 40도가량 보상을 하게되고 타겟에러는 5도이내로 감소하게 됨(적응)
이 때 참여자들에게, 45도의 왜곡이 포함되어 있음을 명시적으로 알려주면 참여자들은 -45도의 수행 전략을 적용하게 되며 즉시 에러는 0으로 감소함.
흥미로운 것은, 연습을 반복하면 에러가 증가하기 시작한다는 것. (반대방향으로)
명시적으로 참여자들은 perturbation r = 45임을 알게 되었지만,
그들의 모터시스템(implicitly)이 추정하고 있는, , approximately equal to zero 임.
을 추정하는 것은 SPE를 통해서 이루어질 수 있는데, 명시적으로 그 결과값을 알려준 것임. 하지만, 운동시스템은 명시적으로 주어진 을 사용하지 않음. (스스로 만들어 내기 위해 작동함)
관찰된 감각귀결 y와 운동명령에 기반하여 예측한 감각귀결 은 여전히 일치하지 않음
→ 0이 아님.
ch 6.5 A generative model of sensorimotor adaptation experiments
명시적인 것과 암묵적인 것의 사이에서
샤드머는 explicit한 것과 implicit한 것의 차이를 인식하고 있음. *중요성을 인식한다고 하자.
HM에 대한 연구: 새로운 명시적 기억을 생성할 수 없는 환자(HM)도 forcefield adaptation은 학습할 수 있었음.
forcefield adaptation 실험에서 참여자들이 학습하는 것은 외력을 보상하기 위한 운동명령의 생성을 배우는 것이 아니라, 연습에 기반한 감각-illusion을 배우게 되는 것이다.

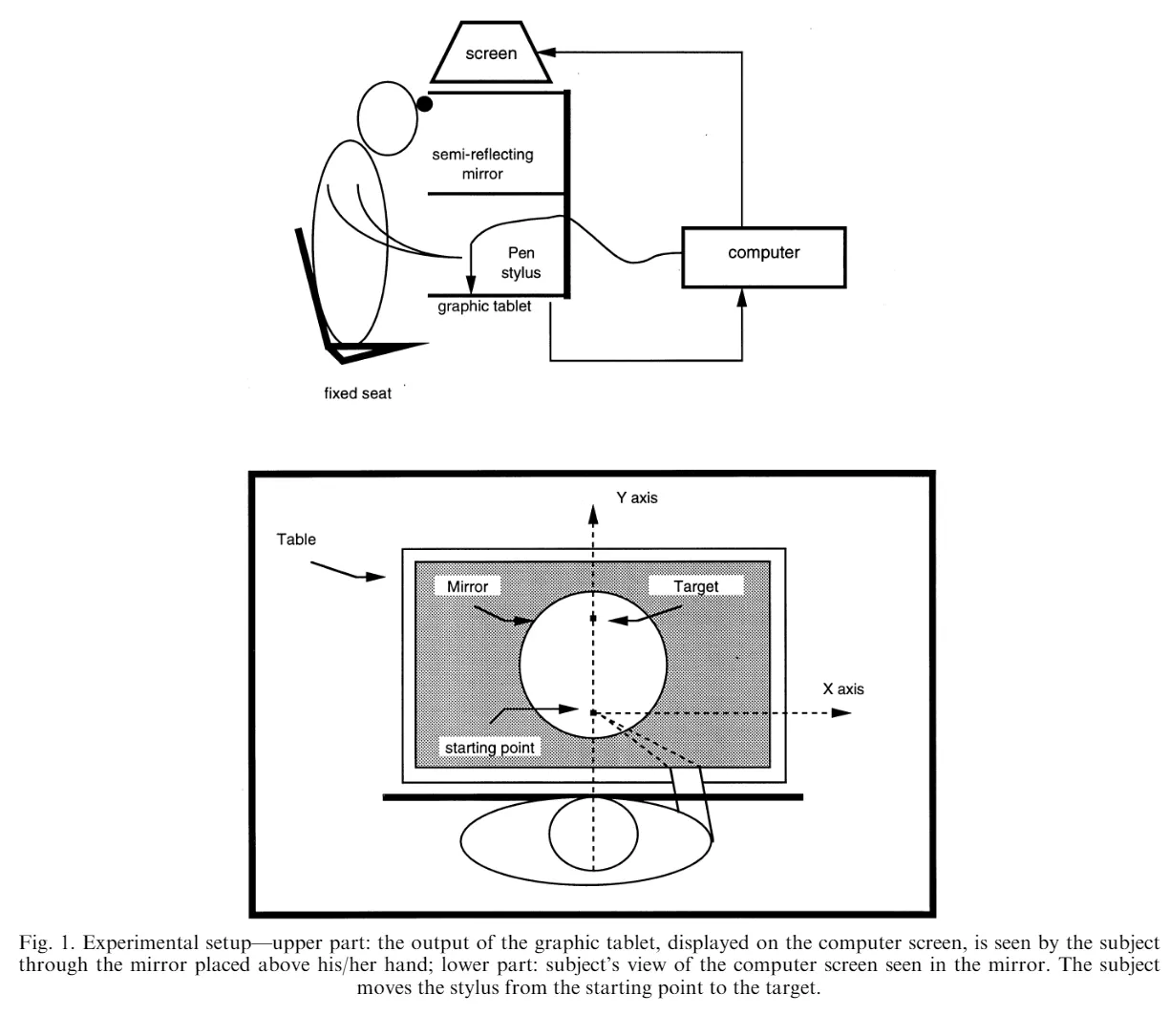
Fourneret의 연구(1998)
Fourneret, P. & Jeannerod, M. (1998). Limited conscious monitoring of motor performance in normal subjects. Neuropsychologia, 36(11), 1133–1140. https://doi.org/10.1016/s0028-3932(98)00006-2

피험자들은 주어진 목표를 향해 손을 뻗었다.
시각 피드백은 손의 움직임에 랜덤한 왜곡이 추가되는 방식으로 제공되었다.
운동 감각적 피드백은 통제조건과 동일하게 제공되었을 것이다.
의식한 손의 움직임 방향에 대한 구두보고에서, 대부분의 피험자들은 시각피드백으로 제공된 손의 움직임과 일치하는 방향으로 자신의 손이 움직였다고 보고하였다.
의식한 손의 움직임 방향에 대한 동작보고에서, 대부분의 피험자들은 “목표지점을 향한 직선”움직임을 보고하였다.

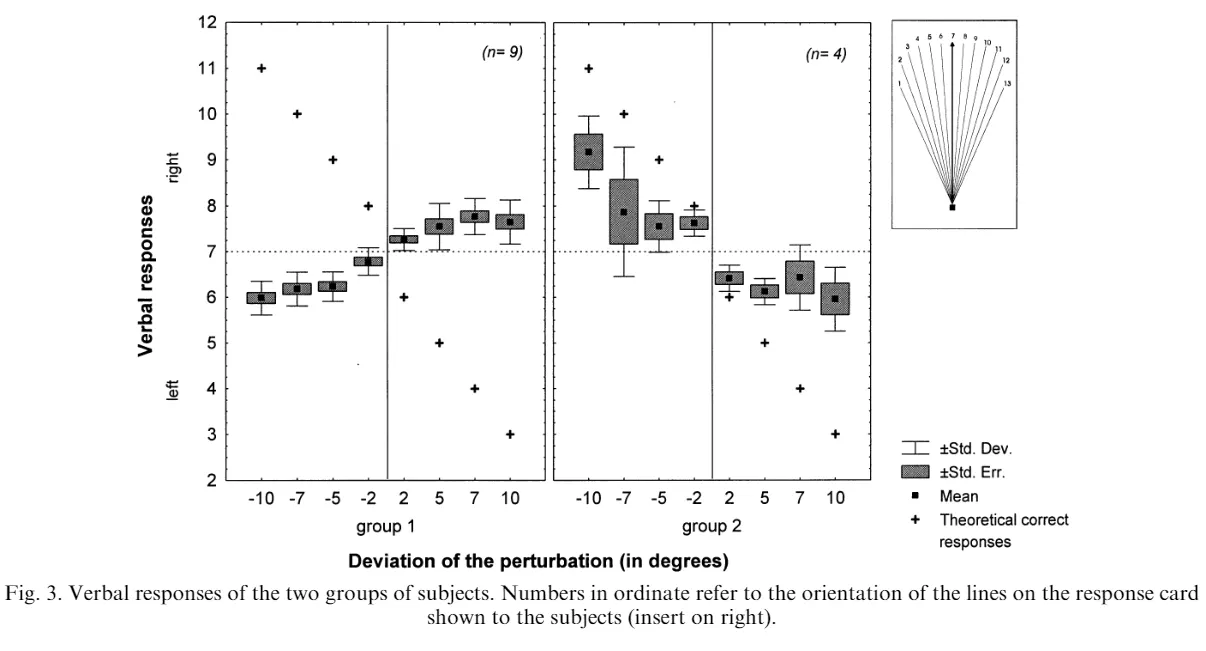
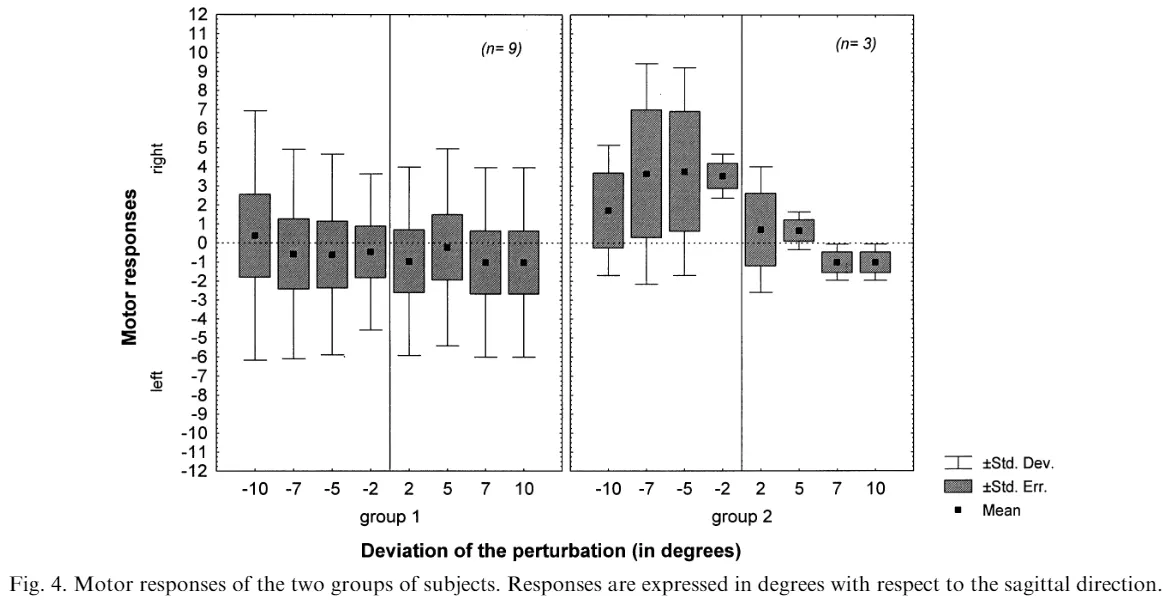
대부분의 사람들은 자신의 손 움직임에 대해 정확히 지각하지 못함.
일부 사람들은 자신의 손 움직임에 대해 비교적 정확한 지각을 가짐.
(이 두 그룹간의 차이는 어디에서 비롯되는 것인가?)
우리는 왜 눈에 보이는 것을 더 믿는가?

운동기술학습
뻗기 동작을 처음 배우는 시기


진행중 과제물 @11/16/2022
•
주유미 교수님 특강
•
감각-운동 적응, 움직임 의식, 운동기술 학습